Building Agent CMO. What AI-native software engineering really requires.
A builder's note on master-agent orchestration, durable product memory, and how senior engineers should use coding agents without letting speed create architectural debt.

There was a point while building Agent CMO when I realized the hard part was no longer getting an AI to write code.
The hard part was giving the work enough structure so the speed did not create more problems than it solved.
That realization changed how I used coding agents. The future of software engineering is not only about asking AI to write code faster. It is about learning how to manage intelligent work.
When I started building Agent CMO, I did not want another marketing tool that generated a few headlines and called itself an AI product. I wanted to build an AI-native marketing operating system that could take a brief, reason through the strategy, produce campaign assets, review its own work, learn from performance, and help decide what to run next.
In other words, the product itself had to work more like an organization than a feature.
The same was true for the way I built it. I had to stop treating coding agents like autocomplete and start treating them like junior engineers, analysts, reviewers, QA specialists, and implementation partners. The quality of the output depended less on the model and more on how clearly I designed the work.
I was partly influenced by an X/Twitter article from Ryan Sarver that was well received because it did something useful and rare. It did not talk about AI agents in vague terms. It explained a real workflow from the perspective of someone actually using agents to extend their operating capacity. The structure was simple and effective: start from a real constraint, show the system that was built, explain the workflow, then share the lessons that other builders can reuse.
That is the spirit of this post. This is not a theoretical essay about AI. It is a builder’s note on what I learned developing Agent CMO, and how software engineers can use coding agents more effectively.
The first mistake is asking an agent to build the product
The worst prompt you can give a coding agent is to ask it to build a complete AI marketing platform.
It feels ambitious, but it is actually lazy. The agent has no product judgment, no sequencing, no architecture context, no acceptance criteria, and no reason to know which decisions matter most.
Early in the process, I forced myself to plan Agent CMO as an orchestration system before thinking about screens or database tables. The initial planning exercise defined the product around a master agent and a set of specialized sub-agents. The important design principle was clear: do not let production agents create assets before strategy agents have locked the brief, audience, positioning, and channel plan.
That principle became one of the foundations of the product.
If you allow content production to happen too early, the system can generate a lot of material quickly. But much of it will be generic, inconsistent, or hard to use. The strategy has to come first. The brief has to become structured data. The audience has to be defined. The positioning has to be sharpened. The assumptions have to be named. Only then should the system produce campaign assets.
This is also how coding agents should be used. Do not ask the agent to write code before you have clarified the architecture, dependency order, success criteria, and constraints.
Agent CMO is built as a coordinated AI workforce
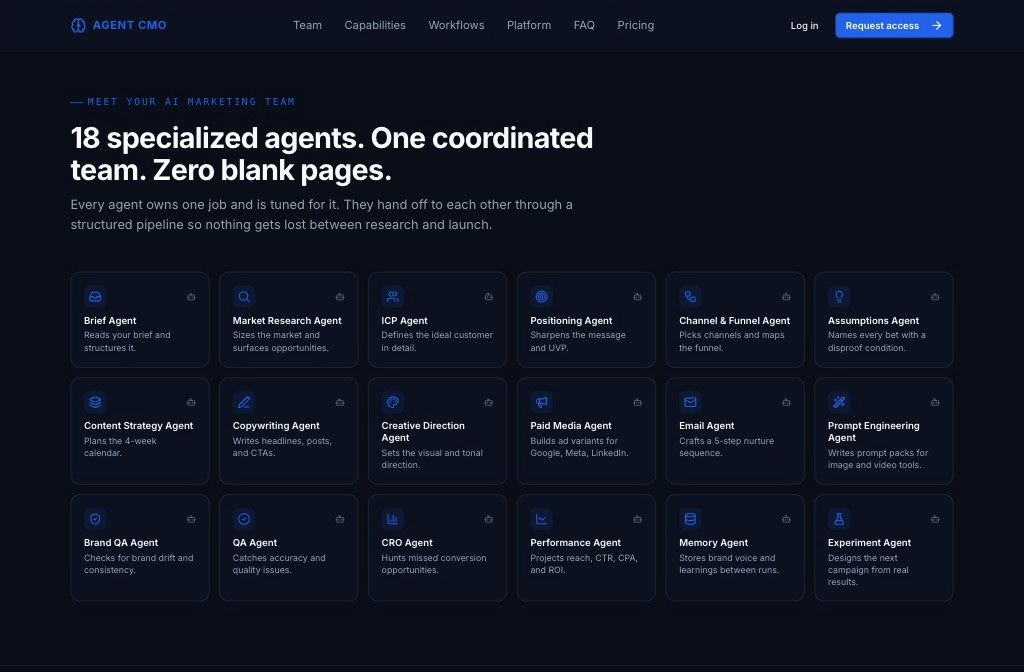
At a high level, Agent CMO is a multi-agent AI marketing operating system. The user drops in a campaign brief, and a coordinated team of 18+ specialized agents researches, plans, writes, designs, reviews, packages, and learns from the campaign.
The master agent acts as the orchestrator. It does not try to do every job itself. Its responsibility is to manage the workflow, maintain the campaign context, enforce dependency order, and route work to the right sub-agent at the right time.
That matters because marketing work is not one task. It is a chain of dependent decisions.
The Brief Agent reads the user’s input and turns it into structured campaign data. The Market Research Agent looks at the market, trends, threats, and opportunities. The ICP Agent defines the target customer in detail. The Positioning Agent sharpens the message and unique value proposition. The Channel & Funnel Agent maps the channels and customer journey. The Assumptions Agent names the core bets and gives each one a disproof condition.
Only after that strategy layer is formed do the production agents begin their work.
The Content Strategy Agent creates the campaign calendar. The Copywriting Agent writes headlines, social posts, calls to action, and core campaign copy. The Creative Direction Agent sets the visual and tonal direction. The Paid Media Agent builds ad variants for platforms such as Google, Meta, and LinkedIn. The Email Agent creates a five-step nurture sequence. The Prompt Engineering Agent produces prompt packs for image and video tools.
Then the governance layer checks the work.
The Brand QA Agent looks for brand drift. The QA Agent checks accuracy and quality issues. The CRO Agent looks for missed conversion opportunities. The Performance Agent projects reach, CTR, CPA, ROI, and prioritized A/B tests. The Memory Agent stores brand voice and learnings across campaigns. The Experiment Agent turns real results into the next campaign hypothesis.
The point is not that each agent has a clever name. The point is that each agent owns a bounded job.
That is what makes the system useful.
The product had to learn, not just generate
A lot of AI products still behave like disposable chat sessions. You ask for something, receive output, copy it somewhere else, and lose the context.
Agent CMO was designed around a different loop.
The platform takes in a brief, runs a nine-stage agent pipeline, produces reviewed and packaged assets, accepts real performance data, extracts learnings, and proposes the next experiment. The campaign does not end when the copy is generated. It continues into monitoring, learning, and iteration.
This is why the Memory Agent and Experiment Agent are not optional features. They are part of the core product philosophy.
A marketing system should remember what worked. It should remember what failed. It should remember approved brand voice, killed assumptions, audience insights, and lessons that should shape the next campaign. Otherwise every campaign starts from zero again.
That was one of the main product decisions behind Agent CMO. The value is not only speed. Speed matters, but compounding context matters more.
How I planned the development work
The development process followed the same logic as the product.
Instead of asking a coding agent to build the whole application in one pass, I separated the work into ordered workstreams. This applied whether I was working through coding agents directly, using Replit as part of the development environment, or reviewing implementation details myself. Each workstream had a clear purpose, a set of files or components it was allowed to touch, and a definition of what completion looked like.
The initial planning focused on the agent architecture, the master-agent orchestration model, and the major capability groups: strategy, channel planning, creative production, governance, intelligence, and memory.
The later continuous development plan broke implementation and integration work into more practical streams. There were separate workstreams for pipeline implementation, API and database behavior, form and input validation, frontend and UI flows, admin access control, homepage SEO readiness, performance bottlenecks, and security checks.
This sounds obvious, but it is where many engineers lose time with coding agents. They give one large instruction, receive a large diff, then spend hours trying to understand what changed.
I prefer a different pattern.
Give the coding agent one meaningful unit of work. Tell it the context. Tell it what not to change. Ask it to produce a plan. Review the plan. Let it implement. Then verify the implementation with tests, logs, type checks, screenshots, or manual inspection. In environments like Replit, this discipline matters even more because the agent can move quickly across files, dependencies, and runtime behavior. Speed is useful only when the scope is controlled.
That workflow feels slower at first. It is faster over a real project.
The architecture also had to support agentic work
Agent CMO is implemented as a pnpm monorepo with three main artifacts behind a path-routed reverse proxy. The web application runs on React, Vite, Tailwind, and Wouter. The API server runs on Express, Node, Drizzle, and Postgres. A separate mockup sandbox supports component preview work.
The shared libraries matter because they reduce drift. The database schema and Postgres client live in one shared library. The OpenAPI contract generates React Query hooks and Zod schemas. Provider integrations are separated into their own packages for OpenAI, Google Drive, Dropbox, Clerk, and other external services.
That structure was important because agentic applications need clear boundaries. If everything is mixed together, the coding agent has too many ways to solve the same problem. That creates inconsistent patterns, duplicated logic, and fragile integrations.
A good codebase gives the agent fewer places to be clever.
The pipeline jobs are persisted in the database and executed by an in-process worker inside the API server. Authentication and approval are handled through Clerk. Campaign files can route through app storage, Google Drive, or Dropbox, depending on plan permissions and user OAuth state. Admin users can manage pricing plans, approvals, CMS pages, payment gateways, social links, and pipeline queue visibility.
None of these decisions were just implementation details. They shaped how reliably the agent pipeline could operate as a product.
What worked best when using coding agents
The most important lesson is that coding agents perform best when the engineer behaves more like a technical lead than a prompt writer.
You cannot outsource judgment. You can outsource execution, exploration, refactoring, test generation, scaffolding, documentation, and code review support. But you still need to decide what matters, what order things should happen in, and what trade-offs are acceptable.
Several practices consistently improved output quality. Start with architecture before implementation, because agents produce better code when they know the intended boundaries and dependency order. Break work into separate workstreams, because smaller scopes reduce unintended changes and make verification easier. Write acceptance criteria before code, because the agent needs to know what success means before it starts changing files.
Separate strategy, production, and review tasks. The same agent session should not plan, build, and approve its own work without checks. Use the codebase’s existing conventions, because agents are much stronger when asked to extend patterns instead of inventing new ones. Verify every meaningful change, because type checks, tests, screenshots, logs, and manual review are still the engineer’s responsibility. Keep memory outside the chat when possible, because durable files, specs, TODOs, and implementation notes prevent context loss.
The last point is especially important. A long chat history is not a reliable engineering system. I found it much more effective to maintain explicit planning files, workstream files, verification notes, and constraints that could be reused across sessions.
That is also why the Agent CMO product itself emphasizes structured envelopes, campaign reports, memory, and transparent stage status. Durable context is what turns one-off generation into an operating system.
The best coding agent workflow mirrors a good engineering team
A strong engineering team does not throw every task into one Slack message and hope for the best. It separates discovery, architecture, implementation, review, QA, release, and monitoring.
Coding agents need the same discipline.
When I used agents effectively, I usually followed a consistent sequence. First, I asked the agent to read the relevant files and summarize the current behavior. Then I asked it to propose a minimal implementation plan before editing code. After that, I asked it to identify exactly which files should change and which should not.
Only then did I let it implement the smallest coherent change that satisfied the plan. After implementation, the work had to be verified through checks, inspection, and evidence. The final step was documentation and handoff, which meant updating the relevant README, API contract, implementation note, or next-workstream instruction.
This pattern helped prevent the most common failure mode: impressive-looking code that does not actually fit the system.
Coding agents, including agentic development environments such as Replit, can write and modify code quickly. That is not the hard part anymore. The hard part is directing the work so that speed does not create architectural debt.
What I would tell software engineers building with agents
If you are a software engineer using coding agents, do not measure success by how much code the agent writes. Measure success by how little confusion the agent creates.
The best agent sessions have a clear task, a clear context window, a clear output, and a clear verification method.
I would treat every coding agent instruction like a ticket for a capable but unfamiliar teammate. Give the background. State the goal. Define the constraints. Point to the relevant files. Explain the expected behavior. Ask for a plan before implementation. Then review the result like you would review any pull request.
If the agent makes a mistake, do not just correct the code. Improve the instruction system that allowed the mistake. Add a convention. Add a test. Add a note. Split the workstream. Narrow the scope.
That is how you get better over time.
Agent CMO is also a lesson in product design
Building Agent CMO reminded me that AI-native applications are not defined by having a chat box. They are defined by whether the system can take responsibility for a meaningful workflow.
A real AI-native product should have memory, task ownership, review loops, structured outputs, orchestration, and a way to improve from feedback. It should know when to run tasks in sequence and when to run them in parallel. It should expose what it is doing so the user can trust the work. It should produce assets that are ready to use, not just interesting to read.
That is the bar I tried to hold Agent CMO to.
The product starts with a brief, but it does not stop at generation. It researches, plans, produces, reviews, packages, monitors, learns, and recommends the next experiment. The master agent keeps the whole workflow coordinated, while the sub-agents focus on their individual responsibilities.
That is also the way I now think about working with coding agents.
Do not ask one agent to be brilliant at everything. Build the system around clear roles, clean handoffs, and real verification.
Software engineering with agents is not less disciplined than traditional engineering. It is more disciplined, because the cost of vague direction is now multiplied by speed.
The opportunity is enormous. But the advantage will not go to the engineers who prompt the most. It will go to the engineers who can design the work.