What doesn't exist, still doesn't: on data, distribution, and the infrastructure nobody's talking about

I asked an AI agent to plan a day trip.
Not just any trip. A Seoul-to-Busan run on May 15th with a friend visiting from Saudi Arabia, someone I care about getting this right for. That means halal-friendly dining. That means traditional Korean food, not tourist food. That means a restaurant that actually understands what a Muslim guest needs, and does it without compromise.
I gave the agent a single instruction. Something like: Plan the day trip, find the best traditional Hansik restaurant appropriate for my Saudi Arabian friend, prepare a full document with restaurant details, photos, hours, and a Google Maps link.
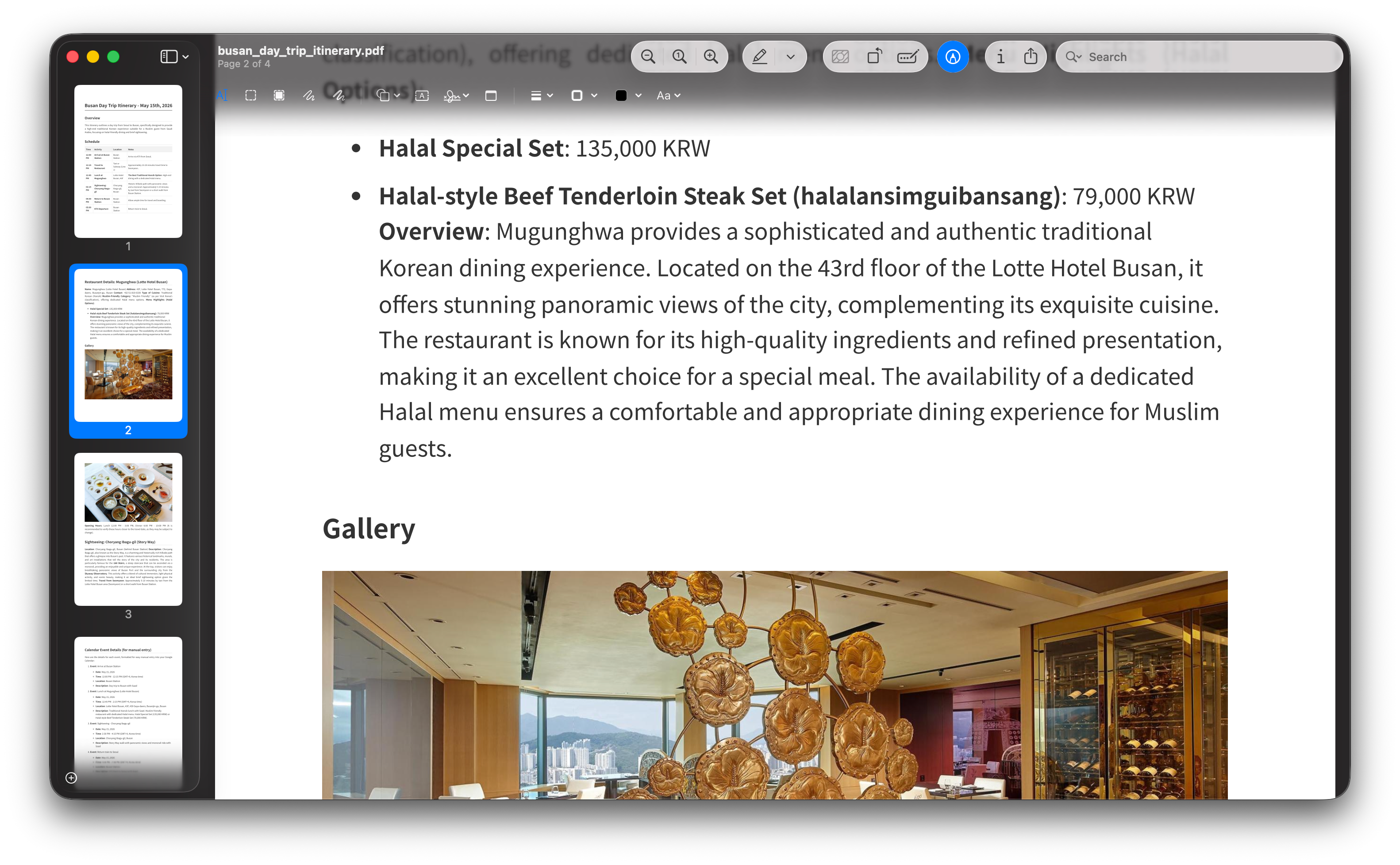
Ten minutes later, I had it all. A clean itinerary that fit my train schedule. A 43rd-floor restaurant overlooking the city with a dedicated halal menu. A scenic hillside walk behind Busan Station with a monorail ride and panoramic views of the port. A document I could hand to my guest and feel proud of.
Distribution is the game. It always has been.
I’ve been thinking about this for a while, and I’ll say it plainly: I believe that in the years ahead, and arguably right now, what separates organizations is not the quality of their product. It is their brand, their distribution, and the community they’ve built around.
This is true for a solo entrepreneur. It is true for a startup. It is true for an agency. And it is especially true in the technology industry, where product engineering, product marketing, and product sales are becoming more commoditized by the month.
The rise of AI agents is accelerating this. When any motivated founder with a clear head and the right tools can build a capable product in weeks, the product itself is no longer your moat. What you’ve built around it, the trust, the reach, the relationships, the information architecture that makes it actually useful, that is the moat.
I’ve understood this intuitively for years. But it wasn’t always obvious what that looked like in practice.
Back in May 2018, after about a year of living in Singapore, I kept running into the same quiet frustration. Singapore’s hawker centres, these incredible community food halls that are genuinely part of the national identity, had a government dataset behind them. Rich, structured, useful information. But accessing it required wading through bureaucratic formats that weren’t designed for developers, and certainly not for anyone who wanted to build consumer-facing experiences on top of them.
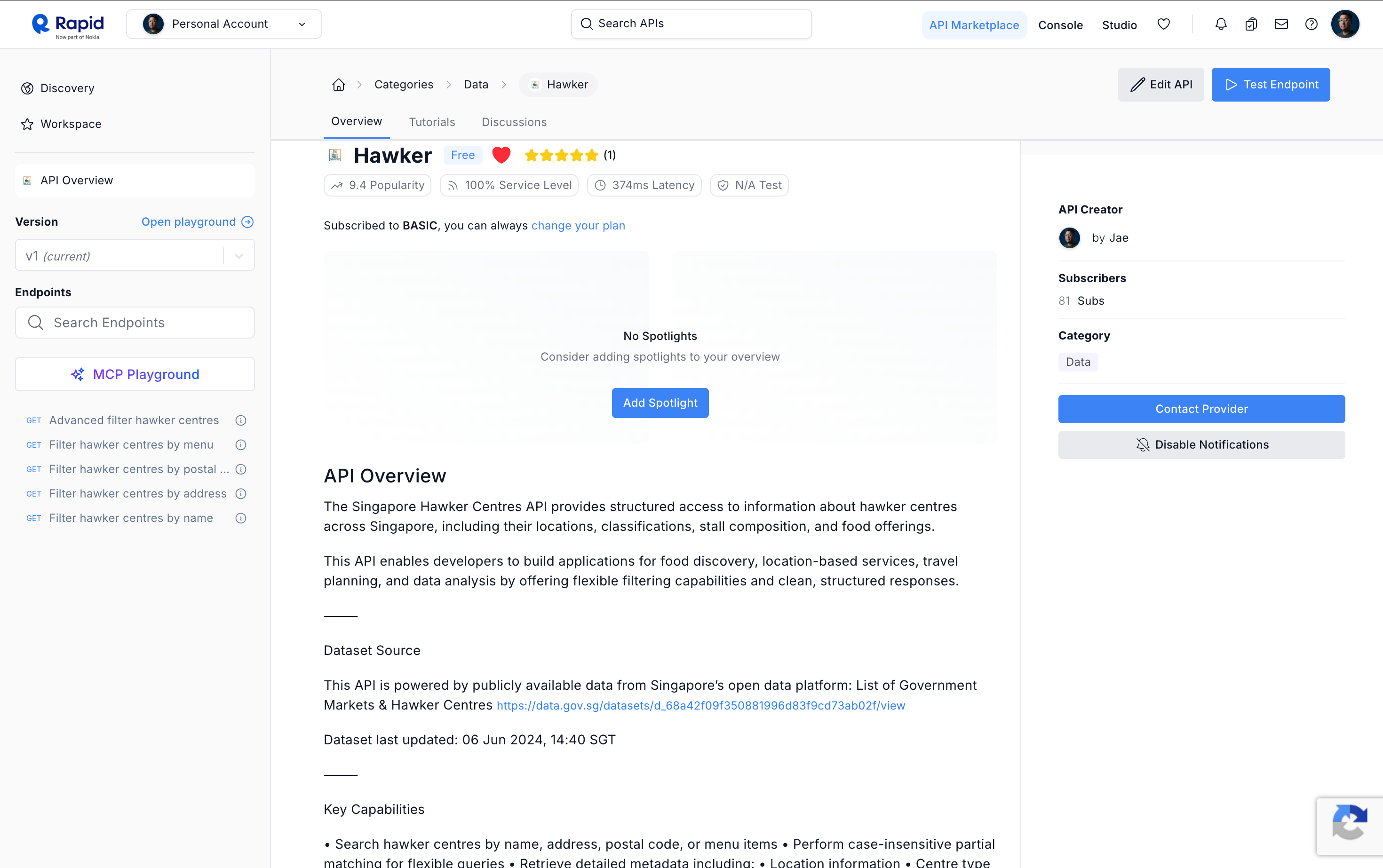
So I built a fully managed API. Clean, structured, searchable access to Singapore’s hawker centre dataset, published on RapidAPI. It wasn’t a product in the traditional sense. It wasn’t meant to be a business. It was a distribution layer. A bridge between data that existed and the experiences that could exist, if someone just made it accessible.
That’s what I was solving. Not a product problem. A protocol problem.
The gap nobody keeps score on
I came across a TripAdvisor report that named Seoul the top destination for solo travelers for 2025. Knowing what I know about Seoul, this didn’t surprise me. But it did make me think harder.
The travel industry has been reshaped. Experiences have become the product. Personalization isn’t a feature, it is the expectation. Skift’s research makes this clear: personalization runs through virtually every major travel industry trend right now, from loyalty to AI adoption to competitive differentiation. Travelers don’t want to be routed through a generic experience anymore. They want something that sees them.
That creates enormous pressure for operators in the travel space to move faster and know more. And it creates an interesting opening for builders.
Because here’s the thing that doesn’t get talked about enough: the data and information that would enable great personalized experiences often exists. It exists in government databases, in tourism boards’ content systems, in local business registries, in cultural heritage records. The problem isn’t that the information isn’t there. The problem is the shape it’s in, and the protocols through which it can be reached.
This is why I built and open-sourced the VisitKorea MCP server.
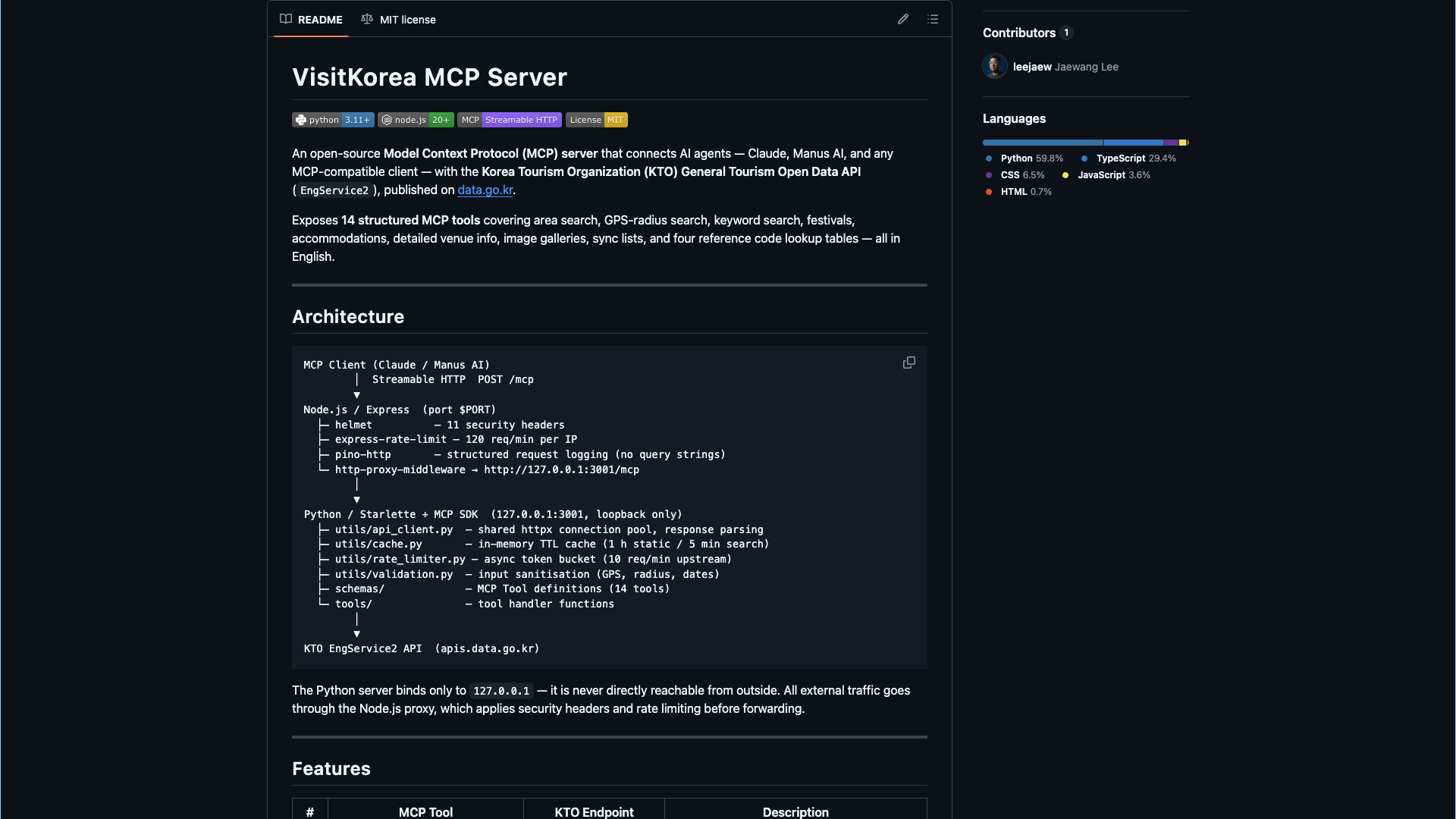
Korea Tourism Organization has a rich API. But making it genuinely useful for AI agents, for the kind of orchestrated, multi-step, context-aware workflows that can actually power meaningful personalized experiences, requires bridging a gap. The MCP (Model Context Protocol) server I built wraps Korea’s tourism data in a format that AI agents can natively understand, query, and act on. It’s published on GitHub under MIT license. Free for personal use, free for commercial use. Anyone building on it, take it.
And when I connected it to an AI agent like Anthropic Claude or Manus AI, paired with a skill built to manage my calendar and plan travel workflows, ten minutes became enough to produce something I’d feel proud handing to a guest.
The infrastructure nobody’s celebrating
Here’s where I’ll say something that probably won’t trend.
Data centers are getting all the headlines. Energy infrastructure for AI compute is a legitimate and important conversation. I understand why it’s dominating the room. But there is another layer of infrastructure that I believe is just as important and far less resourced: the work of making existing data usable.
There is an enormous amount of information in the world, structured, semi-structured, unstructured, sitting in systems that were never designed to talk to AI agents. Government data portals. Tourism content management systems. Healthcare records. Logistics databases. Financial registries. This information is real. It is often accurate. It is often valuable. But it exists in formats, behind protocols, and within technical architectures that make it invisible to the generation of tools being built right now.
LLMs will not solve this on their own. Even the best large language models, when asked about specific and accurate local information, require a retrieval layer. That’s why RAG, retrieval-augmented generation, is so widely adopted today. The model does not know your local hawker centre. It does not know Korea’s regional tourism data. It does not know the halal certification status of a restaurant on the 43rd floor of a hotel in Busan. Not reliably. Not in the shape you need.
Someone has to build the bridge.
What I believe about software’s future
I still believe it’s meaningful to build software. I want to be clear about that. But the terminal value that software once commanded, the idea that a well-engineered product, by virtue of being well-engineered, would naturally compound into a durable business, I think that assumption needs to be updated.
The cost to build is falling. Fast. The expectation for what software should do is rising. Just as fast. That’s not a pessimistic statement. It’s actually an invitation. The ceiling is higher. But the floor has moved too. You can’t compete on “we built a thing” anymore. You compete on brand, distribution, community, and whether the information that powers your experience is accurate, contextual, and genuinely useful.
What I built with the Hawker API in 2018 and the VisitKorea MCP in 2026 is the same instinct applied twice, across different times and technologies. The instinct is this: if the data exists but the access doesn’t, build the access layer. That’s distribution. That’s infrastructure. That’s how you become useful in a world where models are powerful but only as smart as the information they can reach.
What doesn’t exist, still doesn’t. Until someone decides to build it.